
A Dev Kafka Broker for the Price of a Bad Coffee
Running a real Kafka broker for Sentinel's ingestion layer — without the managed service price tag

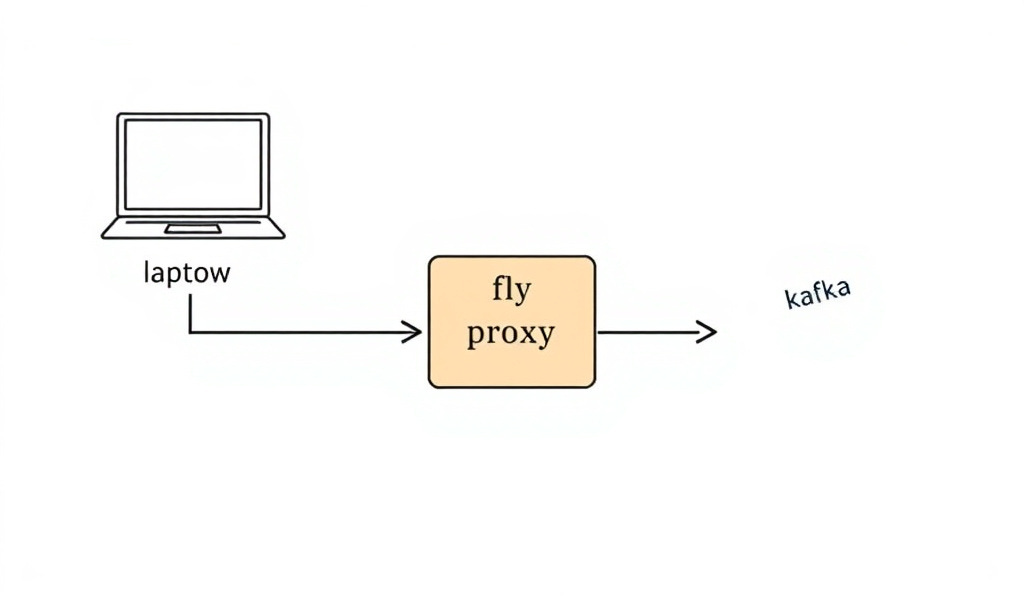
Deploying Kafka on Fly.io
Before I could wire Kafka into Sentinel’s ingestion layer, I needed a Kafka broker that wasn’t going to cost me $50/month to leave running while I figured things out.
AWS MSK? Overkill for dev work. I need something in the middle — a real bro…